微软展示LLaVA-Med模型,可用于医学病理案例分析
来源:AICG工具箱 责编:网络 时间:2025-06-04 13:35:29
6月14日报道 | 微软研究人员最近展示了LLaVA-Med模型,该模型是专为生物医学研究而设计的人工智能模型。它利用生物医学图像,如CT和X光图像等,推测患者的病理状况。微软与一批医院合作,获得了大量的生物医学图像和对应的文本数据集,用于训练这个多模态AI模型。

视觉指令调整,在生物医学领域构建具有 GPT-4级别功能的大型语言和视觉模型。6月1日在GitHub上发布了LLaVA-Med: Large Language and Vision Assistant for Biomedicine,这使得模型能够生成与图像相关的问答,并能够以自然语言回答有关生物医学图像的问题,实现了助手的愿景。
LLaVA-Med模型是基于GPT-4、Vision Transformer和Vicuna语言模型的。微软研究人员使用了八个英伟达A100 GPU对模型进行训练,其中包含每个图像的所有预分析信息。LLaVA-Med 使用通用模型 LLaVA 进行初始化,然后以课程学习方式不断进行训练(首先是生物医学概念对齐,然后是全面的指令调整)。并评估了 LLaVA-Med 在标准视觉对话和问答任务上的表现。

在训练过程中,LLaVA-Med模型主要关注描述图像内容以及阐述生物医学概念(即从图像中判断是什么)。微软表示,该模型在多模态对话能力方面表现出色,并在用于回答视觉问题的三个标准生物医学数据集上,在部分指标上领先于其他先进模型。

然而,微软的研究团队也指出,LLaVA-Med模型目前仍存在一些不足之处。这些包括大模型常见的虚假举例和准确度不佳的问题。研究团队表示,他们将致力于改善模型的质量和可靠性,以便将来能够在商业生物医学领域应用该模型。
尽管LLaVA-Med模型还存在改进空间,但它代表了构建有用的生物医学视觉助手迈出的重要一步。随着微软和其他研究机构的努力,相信在不久的将来,这样的模型将能够为医学界提供更准确、高效的病理分析和诊断服务。

- 常用AI 共 188 款
- 工具箱 共 218 款
- 最新消息 共 1906 款























-
TensorRT插件安装_TensorRT插件怎么提升SD生图速度_stable diffusion插件
本地SD部署速度一直被大家诟病,本次视频就给大家分享Tensorrt插件是如何秒变“5090”,让你的显卡生图速度提升4倍!
-
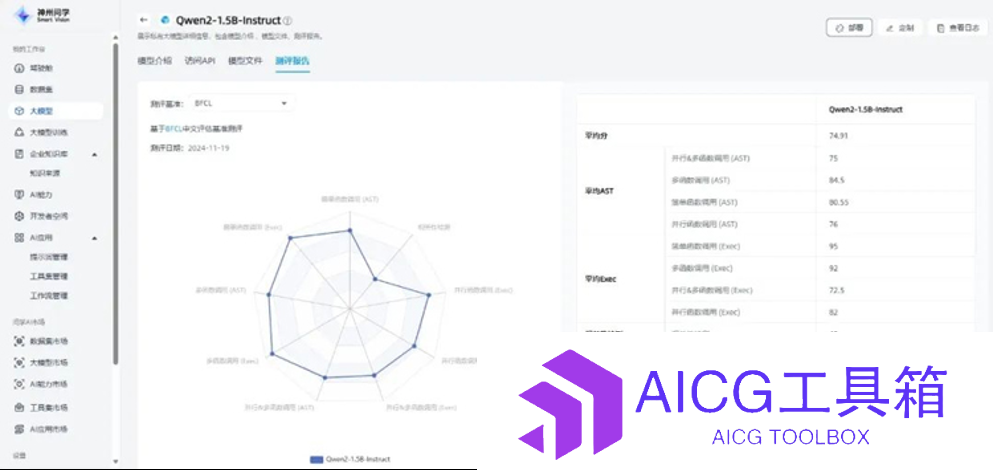
神州问学深入大模型微调技术研究,小参数的模型在特定任务场景中表现超越大模型
在这个时代里,不是模型越大越好,而是更加贴合实际应用场景的小型化、定制化模型正在成为主流。
-
DeepL推出新一代翻译编辑大模型:翻译质量超越竞争对手谷歌微软ChatGPT
DeepL 发布了新一代面向翻译和编辑应用的大型语言模型。据 DeepL 官方称,该模型在翻译质量和流畅度方面均优于当前市场上的其他竞争对手。

-
落地发绿卡?微软加速AI团队撤出中国,加码布局投资东南亚市场
关于微软撤离中国AI团队这件事,或许早有预兆。目前,在AI研究方面,微软正在对中国区的员工进行一定的技术“隔离”。




-
TensorRT插件安装_TensorRT插件怎么提升SD生图速度_stable diffusion插件
11 2025-05-08 -
阿里“通义听悟”升级:支持6小时超长视频内容解析提问,还可一键生成巨幅思维导图
5 2025-04-20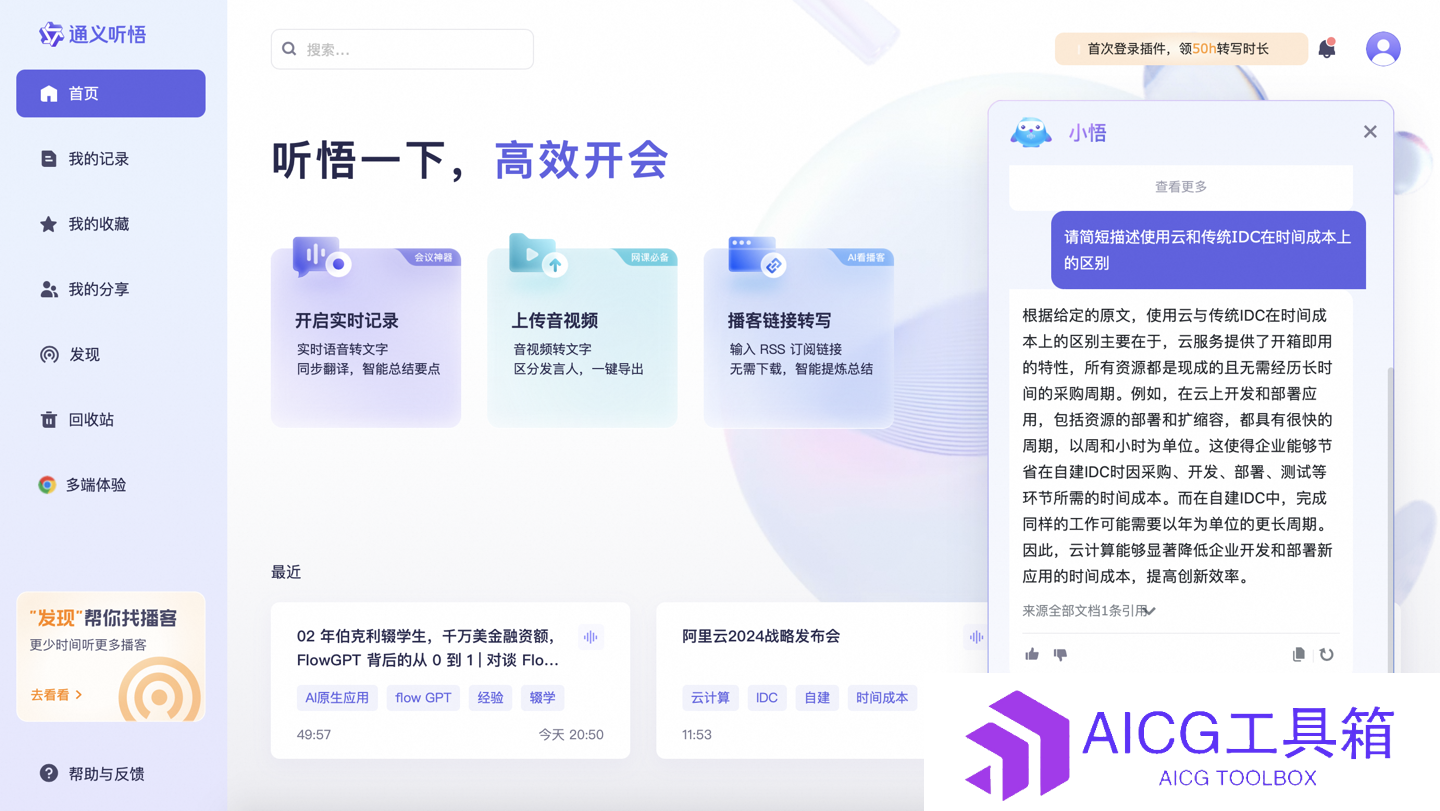
-
苹果与OpenAI合作,发布新版Siri与生成式AI功能丨马斯克宣布将禁用iPhone丨OpenAI百万年薪挖角谷歌芯片人才
16 2025-02-25
-
华为HDC 2024大会将发布盘古大模型5.0丨谷歌Gemini手机版将迎来多项功能更新丨马斯克xAI计划融资60亿美元
5 2025-04-14
-
苹果WWDC定档6月10日将发布AI战略丨中国时报:苹果与百度尚未达成AI合作丨抖音发布AI数字人治理公告
9 2025-04-18
-
OpenAI CEO奥特曼最新讲话汇总,再次曝光GPT-5细节:性能飞跃超乎想象,低估它的人都会被吓傻
5 2025-04-20 -
李开复:最好的AI大模型已经达到人类平均智商的三倍,“杀手级应用”已经出现
3 2025-04-20
-
重磅!英伟达正式官宣「AI核弹级」芯片B100,性能比H100强两倍的H200将于2024年第二季度出货
3 2025-04-20
-
面对Sora训练数据来源一问三不知!OpenAI遭遇成立以来最为惨烈的公关灾难
4 2025-04-20
-
英伟达发布AI算力芯片B200丨高通发布第三代骁龙8s处理器丨李开复:目前最好的大模型已达人类平均IQ的三倍
3 2025-04-20







