研究警示:使用AI生成的内容训练可能导致模型崩溃
来源:AICG工具箱 责编:网络 时间:2025-06-04 10:47:29
6月15日报道 | 随着AI生成内容的广泛应用,一个令人担忧的问题开始浮现:当AI生成的内容在互联网上不断增加,并且用于训练模型时,会发生什么?
最近来自英国和加拿大的研究人员对这个问题进行了深入研究,并在开放获取期刊arXiv上发表了一篇相关论文。他们的研究发现令人忧虑,即使用模型生成的数据进行训练会导致生成的模型出现不可逆转的缺陷,被称为"模型崩溃"。

研究人员主要研究了文本到文本和图像到图像的AI生成模型的概率分布。他们得出结论称,从其他模型生成的数据中进行学习会导致模型崩溃,这是一个逐渐退化的过程,随着时间的推移,模型会逐渐忘记真正的底层数据分布。即使在理想的长期学习条件下,这个过程也是不可避免的。
当AI训练模型接触到更多AI生成的数据时,模型的性能会逐渐下降。它会在生成的响应和内容中产生更多错误,并且响应的非错误多样性也会减少。
AI生成数据的"污染"导致模型对现实的感知产生了扭曲。即使研究人员尝试训练模型不要生成过多重复的响应,他们发现模型崩溃仍然会发生,因为模型会编造错误的响应以避免频繁重复数据。

幸运的是,即使在现有的转换器和LLM(语言模型)的情况下,有一些方法可以避免模型崩溃。研究人员强调了两种具体的方法。
首先是保留原始的完全或名义上由人工生成的数据集的副本,并且不要与AI生成的数据混淆。然后,可以定期重新训练模型或从头开始使用完全新的数据集来刷新模型。
第二种方法是将新的、干净的、由人类生成的数据重新引入到训练中,以避免响应质量下降并减少模型中不需要的错误或重复。

然而,研究人员指出,这需要内容制作者或人工智能公司采用一种大规模标签机制或努力来区分人工智能生成的内容和人类生成的内容。
总之,这些研究发现对于人工智能领域具有重要意义,强调了需要改进方法以保持生成模型的完整性随着时间的推移。它们也提醒我们注意未经检查的生成过程的风险,并可能指导未来的研究以制定防止或管理模型崩溃的策略。
- 常用AI 共 188 款
- 工具箱 共 218 款
- 最新消息 共 1899 款























-
TensorRT插件安装_TensorRT插件怎么提升SD生图速度_stable diffusion插件
本地SD部署速度一直被大家诟病,本次视频就给大家分享Tensorrt插件是如何秒变“5090”,让你的显卡生图速度提升4倍!
-
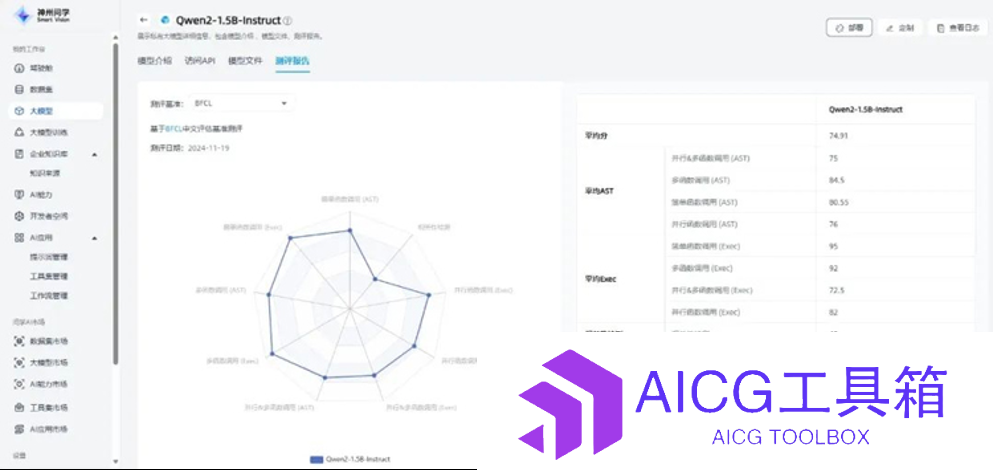
神州问学深入大模型微调技术研究,小参数的模型在特定任务场景中表现超越大模型
在这个时代里,不是模型越大越好,而是更加贴合实际应用场景的小型化、定制化模型正在成为主流。
-
DeepL推出新一代翻译编辑大模型:翻译质量超越竞争对手谷歌微软ChatGPT
DeepL 发布了新一代面向翻译和编辑应用的大型语言模型。据 DeepL 官方称,该模型在翻译质量和流畅度方面均优于当前市场上的其他竞争对手。

-
落地发绿卡?微软加速AI团队撤出中国,加码布局投资东南亚市场
关于微软撤离中国AI团队这件事,或许早有预兆。目前,在AI研究方面,微软正在对中国区的员工进行一定的技术“隔离”。




-
TensorRT插件安装_TensorRT插件怎么提升SD生图速度_stable diffusion插件
11 2025-05-08 -
阿里“通义听悟”升级:支持6小时超长视频内容解析提问,还可一键生成巨幅思维导图
5 2025-04-20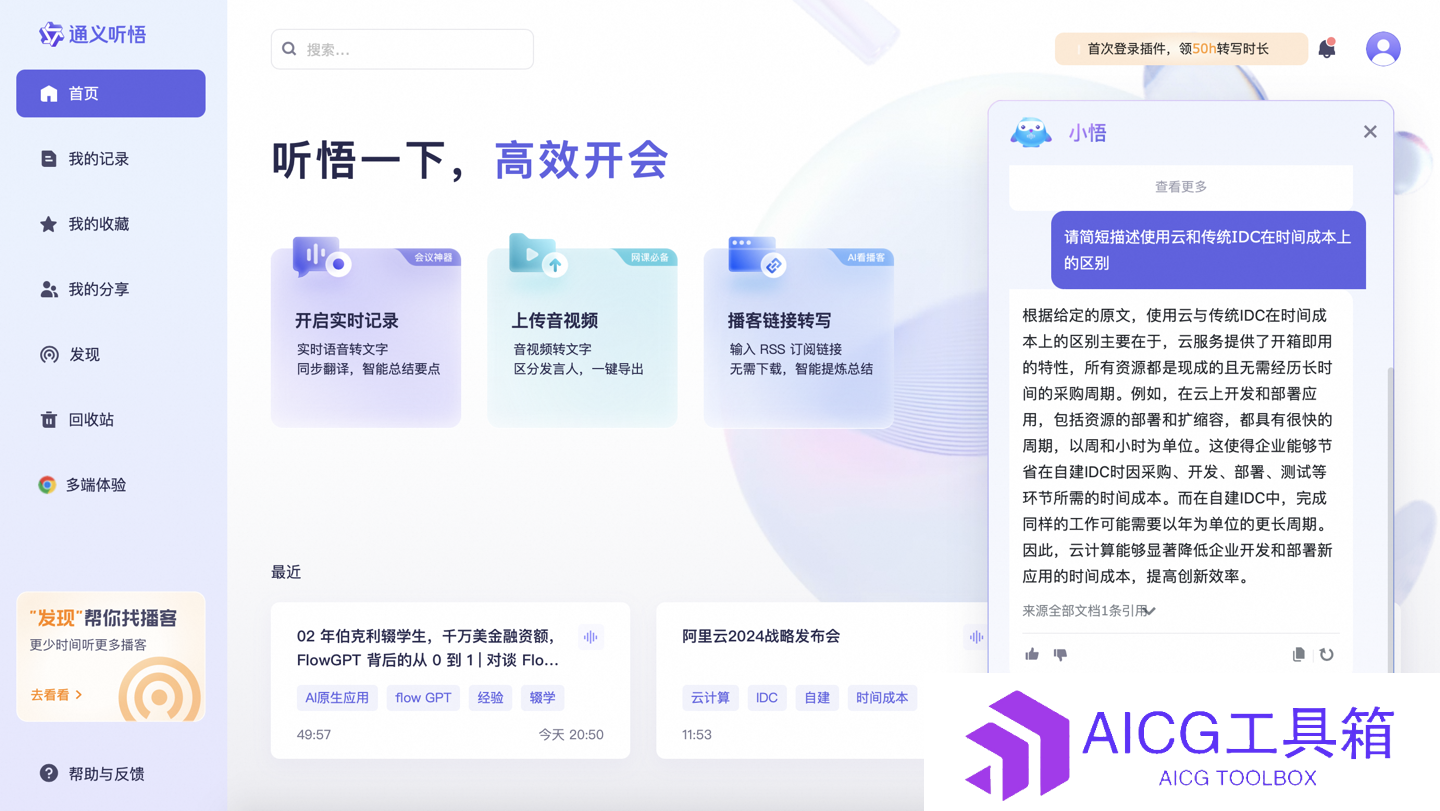
-
苹果与OpenAI合作,发布新版Siri与生成式AI功能丨马斯克宣布将禁用iPhone丨OpenAI百万年薪挖角谷歌芯片人才
16 2025-02-25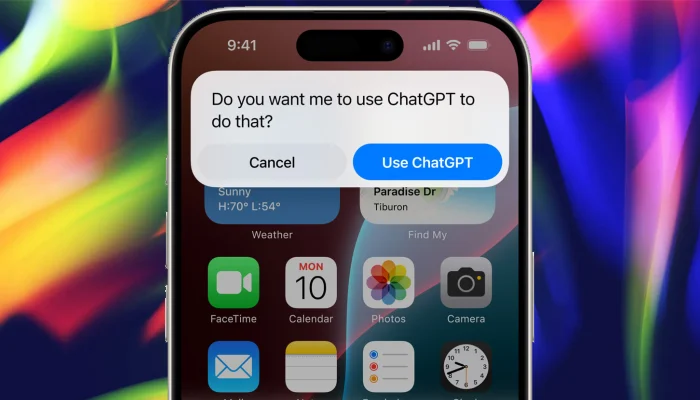
-
华为HDC 2024大会将发布盘古大模型5.0丨谷歌Gemini手机版将迎来多项功能更新丨马斯克xAI计划融资60亿美元
5 2025-04-14
-
苹果WWDC定档6月10日将发布AI战略丨中国时报:苹果与百度尚未达成AI合作丨抖音发布AI数字人治理公告
9 2025-04-18
-
OpenAI CEO奥特曼最新讲话汇总,再次曝光GPT-5细节:性能飞跃超乎想象,低估它的人都会被吓傻
5 2025-04-20 -
李开复:最好的AI大模型已经达到人类平均智商的三倍,“杀手级应用”已经出现
3 2025-04-20
-
重磅!英伟达正式官宣「AI核弹级」芯片B100,性能比H100强两倍的H200将于2024年第二季度出货
3 2025-04-20
-
面对Sora训练数据来源一问三不知!OpenAI遭遇成立以来最为惨烈的公关灾难
4 2025-04-20
-
英伟达发布AI算力芯片B200丨高通发布第三代骁龙8s处理器丨李开复:目前最好的大模型已达人类平均IQ的三倍
3 2025-04-20







