阶跃星辰发布端到端语音大模型Step-Audio2mini,多个基准测试取得SOTA成绩
来源:AICG工具箱 责编:网络 时间:2025-09-06 09:00:00
9月1日消息,阶跃星辰今日发布开源端到端语音大模型Step-Audio2mini,该模型在多个国际基准测试集上取得SOTA成绩。Step-Audio2mini现已上线阶跃星辰开放平台。
从官方介绍获悉,它将语音理解、音频推理与生成统一建模,并率先支持语音原生的ToolCalling能力,可实现联网搜索等操作。
Step-Audio2mini在多个关键基准测试中取得SOTA成绩,在音频理解、语音识别、翻译和对话场景中表现突出,综合性能超越Qwen-Omni、Kimi-Audio在内的所有开源端到端语音模型,并在大部分任务上超越GPT-4oAudio。
在通用多模态音频理解测试集MMAU上,Step-Audio2mini以73.2的得分位列开源端到端语音模型榜首;
在衡量口语对话能力的UROBench上,Step-Audio2mini在基础与专业赛道均拿下开源端到端语音模型最高分,展现出优秀的对话理解与表达能力;
在中英互译任务上,Step-Audio2mini优势明显,在CoVoST2和CVSS评测集上分别取得39.3和29.1的分数,大幅领先GPT-4oAudio和其他开源语音模型;
在语音识别任务上,Step-Audio2mini取得多语言和多方言第一。其中开源中文测试集平均CER(字错误率)3.19,开源英语测试集平均WER(词错误率)3.50,领先其他开源模型15%以上。
过往的AI语音常被吐槽智商、情商双低。一是“没知识”,缺乏文本大模型一样的知识储备和推理能力;二是“冷冰冰”,听不懂潜台词,语气、情绪、笑声这些“弦外之音”。Step-Audio2mini通过创新架构设计,有效解决了此前语音模型存在的问题。
真端到端多模态架构:Step-Audio2mini突破传统ASR+LLM+TTS三级结构,实现原始音频输入到语音响应输出的直接转换,架构更简洁、时延更低,并能有效理解副语言信息与非人声信号。
Step-Audio2mini模型架构图
CoT推理结合强化学习:Step-Audio2mini在端到端语音模型中首次引入链式思维推理(Chain-of-Thought,CoT)与强化学习联合优化,能对情绪、语调、音乐等副语言和非语音信号进行精细理解、推理并自然回应。
音频知识增强:模型支持包括web检索等外部工具,有助于模型解决幻觉问题,并赋予模型在多场景扩展上的能力。
GitHub:https://github.com/stepfun-ai/Step-Audio2
HuggingFace:https://huggingface.co/stepfun-ai/Step-Audio-2-mini
ModelScope:https://www.modelscope.cn/models/stepfun-ai/Step-Audio-2-mini
- 常用AI 共 188 款
- 工具箱 共 219 款
- 最新消息 共 2791 款























-
有哪些好用的AI工具_AI工具测评使用_
这篇文章,我想好好盘点一下从ChatGPT出现到现在,真正实用且主流的AI工具。包含大语言模型、AI PPT、AI 绘图、AI音频、AI数字人、AI视频这6个部分。
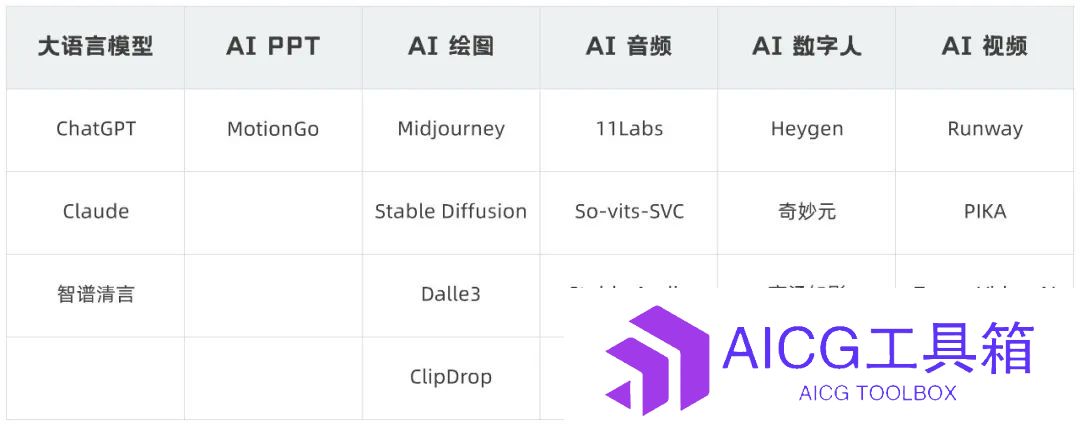
-
xAI融资顺利,马斯克悄然撤诉OpenAI+奥特曼,炒作背后目的令人狐疑
当地时间6月11日,最新消息称,马斯克主动撤销了对OpenAI提起的诉讼。之前指控奥特曼和OpenAI公然违背了创始协议转向盈利。

-
现在张嘴不说Vibe,都不适合在AI圈待了?
过去一个月,你听到了多少次Vibe?如果你关注AI的各种动态,那应该比你过去N年听到的次数都多。从VibeCoding,再到VibeMarketing、VibeInvesting……“Vibe”正在成为AI圈的一种Vibe。有人把它当作技术普

-
GPT-4o回来了,评论区炸了
GPT-4o回归付费用户,用户体验与成本平衡成焦点。



-
xAI融资顺利,马斯克悄然撤诉OpenAI+奥特曼,炒作背后目的令人狐疑
36 2025-02-24
-
现在张嘴不说Vibe,都不适合在AI圈待了?
16 2025-07-01
-
GPT-5 翻车:OpenAI「回滚」大戏与AI扩张隐形边界
5 2025-08-23 -
通义听悟如何使用自定义专有词汇
29 2025-01-23 -
通义听悟如何管理发言人_通义听悟如何管理发言人使用方法
33 2025-01-23 -
通义听悟如何将音视频文件转文字
34 2025-01-23 -
春节前后罗永浩将发布一款AI软件丨马斯克xAI完成新一轮60亿美元融资丨智谱AI×英特尔打造酷睿Ultra专享版
30 2025-01-29
-
马斯克与奥特曼「八年的爱恨情仇」:从兄弟联手创办OpenAI,到理念不合、分道扬镳、相爱相杀、对薄公堂
23 2025-04-25
-
AI走向太空,王坚院士最新演讲,提出“三体计算星座”全球协作倡议
4 2025-08-22 -
DeepMind CEO定义世界模型标准:不仅理解物理世界,还能创造它
4 2025-08-22

