开源版Gemini诞生_全能多模态模型Emu2登热榜_最新Emu2
来源:AICG工具箱 责编:网络 时间:2025-05-03 16:49:32
过去的18个月里,我们见证了AI领域许多重要的时刻。
Llama、Alpaca等众多开源模型竞相发布,不仅与闭源模型的性能相媲美,同时为每个人提供了投身AI的机会:
- 2022年8月,Stable Diffusion问世,让DALL·E的神秘光环不再遥不可及,每个人都能够召唤出自己的数字达芬奇;
- 2023年2月,Meta的Llama及其后续的语言模型大军,让ChatGPT的独角戏成为群星争辉;
- 2023年12月6日,Google DeepMind揭开多模态巨星Gemini的面纱。
仅仅两周后,智源研究院便发布了最新一代生成式多模态开源模型——Emu2.
很快,这一开源多模态领域的工作便引起了国际社区的广泛关注,并登上了HN热榜第三。


Emu2在HackerNews榜单上引发关注

HuggingFace大V AK转发
据悉,这一模型即将推出更轻量的版本,让技术玩家也在本地运行。
Emu2.通过大规模自回归生成式多模态预训练,显著推动了多模态上下文学习能力的突破。
Emu2在少样本多模态理解任务上大幅超越Flamingo-80B、IDEFICS-80B等主流多模态预训练大模型,在包括VQAv2、OKVQA、MSVD、MM-Vet、TouchStone在内的多项少样本理解、视觉问答、主体驱动图像生成等任务上取得最优性能。

Emu2模型和Flamingo、GPT-4V、Gemini等模型能力对比情况一览
「开源版Gemini」来袭
相较2023年7月发布的第一代「多模态to多模态」Emu模型,Emu2使用了更简单的建模框架,训练了从编码器语义空间重建图像的解码器、并把模型规模化到37B参数实现模型能力和通用性上的突破。
与此同时,依然采用大量图、文、视频的序列,建立基于统一自回归建模的多模态预训练框架,将图像、视频等模态的token序列直接和文本token序列交错在一起输入到模型中训练。
值得一提的是,Emu2是目前最大的开源生成式多模态模型,基于Emu2微调的Emu2-Chat和Emu2-Gen模型分别是目前开源的性能最强的视觉理解模型和能力最广的视觉生成模型:
- Emu2-Chat可以精准理解图文指令,实现更好的信息感知、意图理解和决策规划。
- Emu2-Gen可以接受图像、文本、位置交错的序列作为输入,实现灵活、可控、高质量的图像和视频生成。
现在,Emu2的模型、代码均已开源,并提供Demo试用。

项目:https://baaivision.github.io/emu2/
模型:https://huggingface.co/BAAI/Emu2
代码:https://github.com/baaivision/Emu/tree/main/Emu2
Demo:https://huggingface.co/spaces/BAAI/Emu2
论文:https://arxiv.org/abs/2312.13286
多项性能刷新SOTA
通过对多模态理解和生成能力的定量评测,Emu2在包括少样本理解、视觉问答、主体驱动图像生成在内的多个任务上取得最优性能。
在少样本评测上,Emu2在各个场景下显著超过Flamingo-80B,例如在16-shot TextVQA上较Flamingo-80B 超过12.7个点。

经过指令微调的Emu2可以对图像和视频输入进行自由问答,以统一模型在VQAv2、OKVQA、MSVD、MM-Vet、TouchStone等十余个图像和视频问答评测集上取得最优性能。

在零样本的DreamBench主体驱动图像生成测试上,较此前方法取得显著提升,例如比Salesforce的BLIP-Diffusion的CLIP-I分数高7.1%, 比微软的Kosmos-G的DINO分数高7.2%。

多模态上下文学习
生成式预训练完成后,Emu2具备全面且强大的多模态上下文学习能力。基于几个例子,模型可以照猫画虎的完成对应理解和生成任务。
例如在上下文中描述图像、在上下文中理解视觉提示(覆盖图像上的红圈)、在上下文中生成类似风格的图像、在上下文中生成对应主体的图像等。

强大的多模态理解
经过对话数据指令微调的Emu2-Chat,可以精准理解图文指令、更好的完成多模态理解任务。
例如推理图像中的要素、读指示牌提供引导、按要求提取和估计指定属性、回答简单的专业学科问题等。




基于任意prompt序列的图像生成
经过高质量图像微调的Emu2-Gen,可以接受图像、文本、位置交错的序列作为输入,生成对应的高质量图像,这样的灵活性带来高可控性。
例如生成指定位置、指定主体的熊和向日葵:

生成指定位置、指定主体、指定风格的宠物狗和小鸸鹋的合影图像:

更多的根据图文序列生成的例子:
基于任意prompt序列的视频生成
进一步的,Emu2支持基于任意prompt序列的视频生成。
基于文本、图文交错、图文位置交错的序列,可以生成对应的高质量视频。

统一的生成式预训练
Emu2的训练方法是在多模态序列中进行生成式预训练。
使用统一的自回归建模方式,根据当前已生成的 token 预测下一个视觉或文本token。
相比Emu1.Emu2使用了更简单的建模框架、训练了更好的从特征重建原图的解码器、并把模型规模化到37B参数。

- 常用AI 共 188 款
- 工具箱 共 218 款
- 最新消息 共 1255 款























-
商汤全新AI绘图大模型“秒画Artist”v0.3.5版本上手测评:作画水平比肩Midjourney!划重点——免费
商汤科技最新升级的AI文生图领域的预训练模型——秒画Artist v0 3 5版本,三个月后迭代。审美水平和专业度上达到顶尖水平,福利值(免费)直接拉满

-
有什么方式可以运行stable diffusion_怎么用Docker容器运行 SD
Stable Diffusion 是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像。它通过模拟扩散过程,将噪声图像逐渐转化为目标图像。这种模型具有较强的稳定性和可控性,可以生成具有多样化效果和良好视觉效果的图像

-
ChatGPT Plus会员怎么付费_如何升级ChatGPT Plus会员
免费版的 ChatGPT 足以完成大多数任务,但如果想要更快的响应、更多的细节和访问最新的功能,应该考虑获取 ChatGPT Plus。现在Plus版本已经可以连接互联网,获取最新的消息,以及各种各样的小插件,非常好用!

-
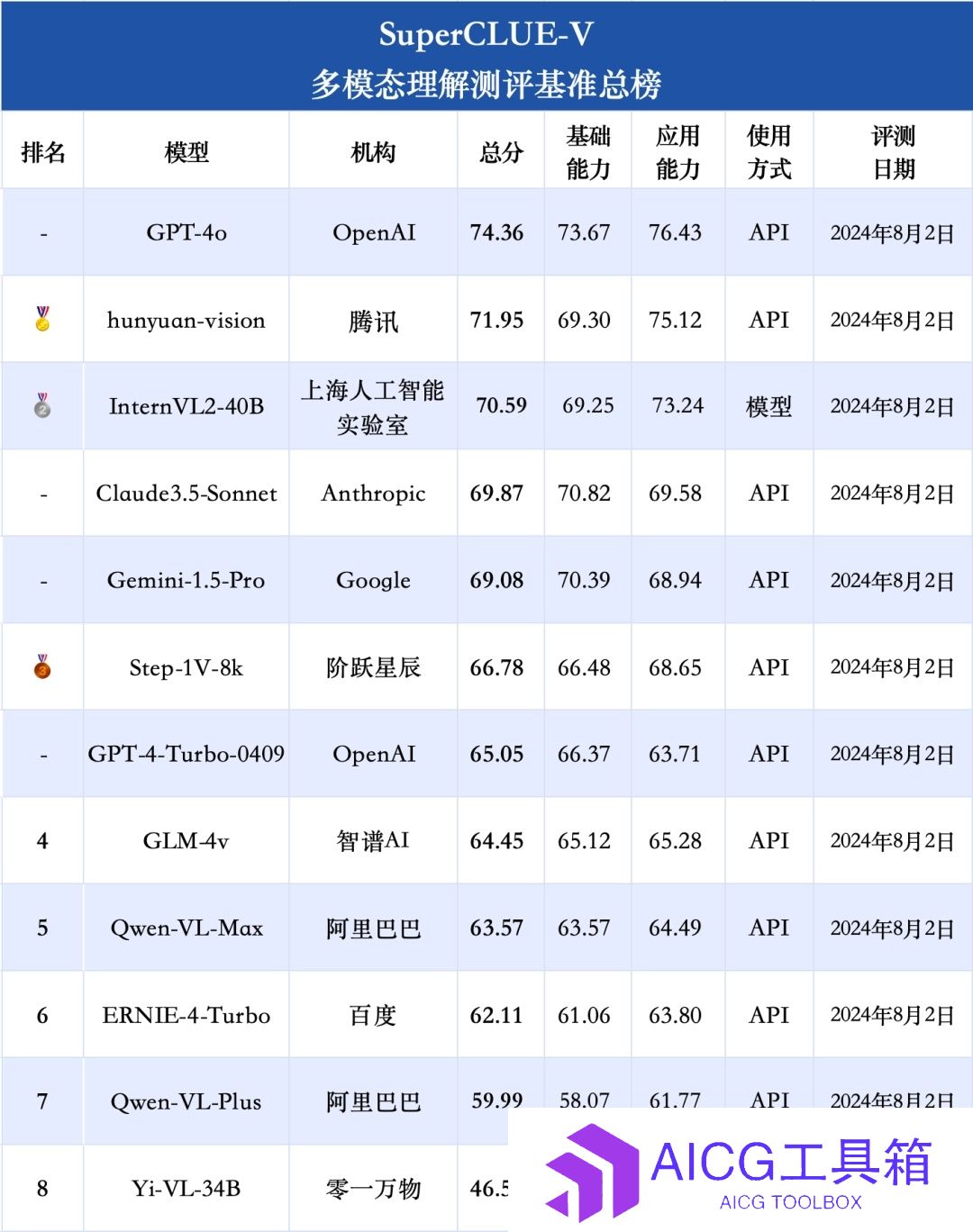
中文多模态大模型SuperCLUE-V榜单发布丨Stability AI推出Stable Fast 3D模型丨Meta AI向好莱坞明星采买声音授权
【AI奇点网2024年8月5日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。




-
ChatGPT Plus会员怎么付费_如何升级ChatGPT Plus会员
20 2025-01-26
-
商汤全新AI绘图大模型“秒画Artist”v0.3.5版本上手测评:作画水平比肩Midjourney!划重点——免费
23 2024-12-31
-
stable diffusion controlnet_stable diffusion模型哪个好
13 2025-01-17
-
ChatGPT计划在年底将订阅费涨到22美元/月丨Llama 3.2发布:手机端侧可运行丨百度世界大会将于11月12日举行
11 2025-02-05
-
字节跳动发布两款豆包系列视频模型丨ChatGPT「高级语音模式」功能全量上线丨「Apple智能」对存储空间要求进一步提高
31 2025-02-05
-
国产最强文生视频模型「可灵」首发:直出2分钟超长视频,生成质量完胜OpenAI Sora丨免费体验
39 2025-02-25
-
快手发布文生视频大模型「可灵」丨广东高考首次启用AI智能巡考丨支付宝推出AI毛发自测工具
22 2025-02-25
-
字节跳动试水AI硬件研发:重整人马聚焦教育赛道与智能可穿戴终端,两条产品线同时推进
4 2025-03-25
-
10年缘分说散就散:Ilya Sutskever官宣从OpenAI离职,麾下的“超级对齐团队”负责人也一并离职
4 2025-03-31 -
ChatGPT年度更新曝光:免费用户升级GPT-4丨华为Pura 70修复「AI消除衣服」BUG丨商汤日日新5.0官网上线
6 2025-04-14