谷歌发布AI视频全能模型Lumiere_迄今为止最强大,画质逆天,水时长第一,流畅一塌糊涂
来源:AICG工具箱 责编:网络 时间:2025-05-01 08:41:36

岁末年初,“硅谷卷王”谷歌再次释出王炸新模型!这次聚焦AI视频生成赛道,要说今年不出一部AI大片我是不信的!

当地时间1月23日,谷歌发布名为Lumiere的新模型,采用了最先进的[时间↔空间]U-Net架构,可以生成高度一致性的完整视频片段。
废话不多说,直接上官方宣传片:
谷歌所谓的「U-Net架构」,简而言之就是在训练大模型的时候,在空间与时间两个维度同时采样,减少AI的“发散思考”,增强画面稳定性,能显著拉长生成视频的长度和质量。

这是谷歌AI团队历时7个月打磨的首个全能视频模型。
长期以来,AI视频生成一直存在诸多的缺陷:运动连贯性和一致性很低,卡成PPT,叠影重重等一系列问题。??

谷歌自研的UNet架构可以生成5秒的视频,比竞品Runway与Pika要多一两秒。
更为重要的是,谷歌视频模型可以生成80帧的片段!不仅画质好、质量高,而且时长更长。

我们来看一些实际案例:


虽然还存在一些瑕疵,但作为首个落地模型已经相当不错了。
谷歌Lumiere视频模型不仅本领强,而且功能更加丰富,效果拔群!
视频局部编辑
这项功能可以让剪辑师快速针对视频画面当中的物体进行替换。
比如这个穿着绿色花点裙的女子,只需选中衣服的区域,输入几个简单的提示词文字,AI系统能瞬间将她的裙子换成红白条纹长裙、金色礼服。

正在晨跑的少女,让她长满鲜花,或者进行风格迁移,将其变成木砖风、折纸风、乐高风。

你甚至可以针对更小的对象进行修改和编辑。
比如,让?猫头鹰戴上眼镜。

视频画面修复
除了修改画面的内容,甚至还可以针对损失局部画面的视频进行填充修补。
右下角的这个案例,充满想象力的AI系统画出了一块毫无破绽的慕斯蛋糕。

文本生成视频
除了视频编辑功能,谷歌Lumiere自然也支持从文本生成视频片段。
画一个在火星基地周边漫步的宇航员。

画一只戴着太阳镜被车拉着走的小狗。

画一座废弃的庙宇,在遗迹中穿行。

图像生成视频
谷歌Lumiere另外一个非常好用的功能,便是将静态图像转换为动态视频。
输入提示词「姑娘微笑和眨眼」?,戴珍珠耳环的少女从名画中走出,咧嘴笑了起来。

梵高《星空》,以令人不可思议的方式流动起来。

图像风格化迁移生成视频
除了一般的“图生视频”,谷歌Lumiere模型还能根据参考图生成特定风格的动态艺术视频。
比如,传一张夜光蘑菇图?,生成各种散发荧光的动物。

再看几个别的案例,生成的视频风格复刻得非常精准。

这对于那些技艺较浅的普通视频作者真是降维打击。
运动笔刷
看到这四个字,熟悉AI视频创作的家人们想必马上联想到Runway Gen-2模型正在内测的相似功能。
?相关阅读:

AI视频可控性里程碑:Runway Gen-2上线「多重运动笔刷」大量实战案例:一键可让五个物体以不同形式运动
AI视频可控性里程碑更新:1月18日,Runway上线了多重运动笔刷,这个功能可以单独控制最多五个笔刷选定的区域。让我们看看那些优秀应用案例。
- 常用AI 共 188 款
- 工具箱 共 218 款
- 最新消息 共 1168 款























-
有什么方式可以运行stable diffusion_怎么用Docker容器运行 SD
Stable Diffusion 是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像。它通过模拟扩散过程,将噪声图像逐渐转化为目标图像。这种模型具有较强的稳定性和可控性,可以生成具有多样化效果和良好视觉效果的图像

-
商汤全新AI绘图大模型“秒画Artist”v0.3.5版本上手测评:作画水平比肩Midjourney!划重点——免费
商汤科技最新升级的AI文生图领域的预训练模型——秒画Artist v0 3 5版本,三个月后迭代。审美水平和专业度上达到顶尖水平,福利值(免费)直接拉满

-
WPS AI表格教程丨Excel办公软件函数公式怎么使用_WPS AI表格公式快速生成!
自从接触WPS AI,我终于体验到老板的快乐,将复杂重复的工作交给AI。AI处理表格数据的效果如何?下面带大家看看AI能力怎样为我们工作吧
-
stable diffusion初识_stable diffusion跟其他工具有什么区别]
关于Stable Diffusion的内容很多,在本篇教程里,我会先为你介绍Stable Diffusion模型的运行原理、发展历程和相较于其他AI绘图应用的区别。
![stable diffusion初识_stable diffusion跟其他工具有什么区别]](//www.aiarticle.cc/uploadfile/2025/0117/d3a1bbf8bad6e281f82a2168727dfba1.png)


![stable diffusion初识_stable diffusion跟其他工具有什么区别]](http://www.aiarticle.cc/uploadfile/2025/0117/d3a1bbf8bad6e281f82a2168727dfba1.png)
-
中文多模态大模型SuperCLUE-V榜单发布丨Stability AI推出Stable Fast 3D模型丨Meta AI向好莱坞明星采买声音授权
38 2025-02-11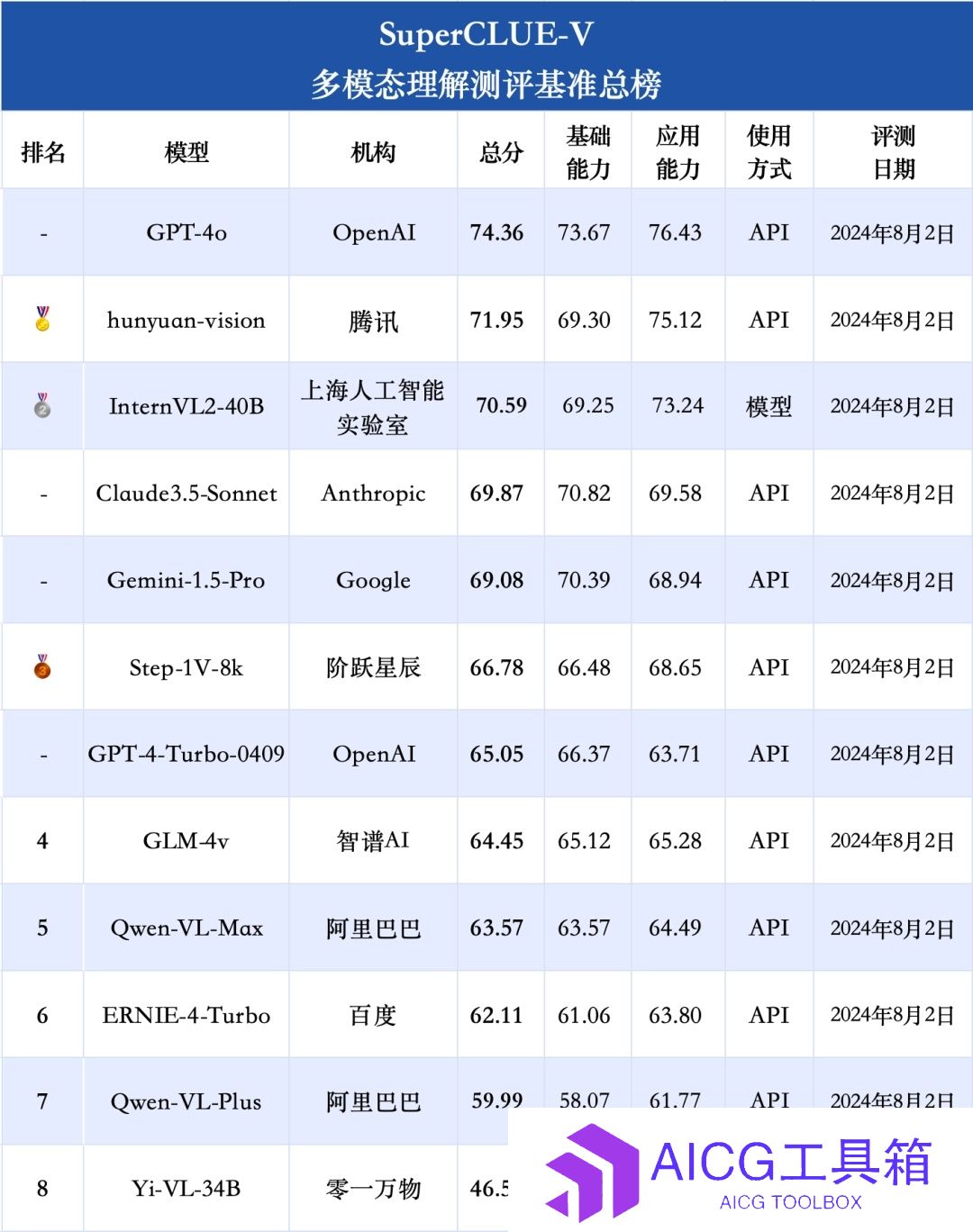
-
科大讯飞星火大模型V1.5升级版首发测评:文本反馈疾速,一项指标“遥遥领先”
11 2025-01-07
-
SD渲染脚本_核显怎么跑stable diffusion_SD
12 2025-01-15
-
小白0基础教程:利用AI视频生成工具,批量制作视频,太爽哦
23 2025-01-15
-
Midjourney 模型如何选择_怎么选择MJ模型
13 2025-01-27
-
ChatGPT计划在年底将订阅费涨到22美元/月丨Llama 3.2发布:手机端侧可运行丨百度世界大会将于11月12日举行
11 2025-02-05
-
字节跳动发布两款豆包系列视频模型丨ChatGPT「高级语音模式」功能全量上线丨「Apple智能」对存储空间要求进一步提高
31 2025-02-05
-
ChatGPT将新增8种语音音色丨小米小爱音箱推送小爱大模型丨阿里通义Qwen2-VL视觉语言模型开源
9 2025-02-07
-
「苹果AI」功能将来会收费,iPhone 16的AI算力将超过AI PC电脑
9 2025-02-19
-
快手发布文生视频大模型「可灵」丨广东高考首次启用AI智能巡考丨支付宝推出AI毛发自测工具
22 2025-02-25