苹果首个多模态大模型MM1曝光:论文上线,300亿参数规模、支持图像内容解读、MoE架构
来源:AICG工具箱 责编:网络 时间:2025-04-20 14:39:45
以下文章来自于丨机器之心
刚刚宣布放弃造车项目的苹果公司,在当今的人工智能(AI)竞赛中落伍了。为了摆脱窘境,苹果近期放弃了造车项目,正在全面转向生成式AI领域,并且很快有了新动作,推出了一款被命名为「MM1」的多模态大模型。

从去年底开始,苹果已经加大了生成式 AI 的重视和投入。此前在 2024 苹果股东大会上,苹果 CEO 库克表示,今年将在生成式 AI 领域实现重大进展。此外,苹果宣布放弃 10 年之久的造车项目之后,一部分造车团队成员也开始转向 AI 业务。
如此种种,苹果向外界传达了加注生成式 AI 的决心。目前多模态领域的生成式 AI 技术和产品非常火爆,尤以 OpenAI 的 Sora 为代表,苹果当然也想要在该领域有所建树。
今日,在一篇由多位作者署名的论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》中,苹果正式公布自家的多模态大模型研究成果 —— 这是一个具有高达 30B 参数的多模态 LLM 系列。

该团队在论文中探讨了不同架构组件和数据选择的重要性。并且,通过对图像编码器、视觉语言连接器和各种预训练数据的选择,他们总结出了几条关键的设计准则。具体来讲,本文的贡献主要体现在以下几个方面。
首先,研究者在模型架构决策和预训练数据选择上进行小规模消融实验,并发现了几个有趣的趋势。建模设计方面的重要性按以下顺序排列:图像分辨率、视觉编码器损失和容量以及视觉编码器预训练数据。
其次,研究者使用三种不同类型的预训练数据:图像字幕、交错图像文本和纯文本数据。他们发现,当涉及少样本和纯文本性能时,交错和纯文本训练数据非常重要,而对于零样本性能,字幕数据最重要。这些趋势在监督微调(SFT)之后仍然存在,这表明预训练期间呈现出的性能和建模决策在微调后得以保留。
最后,研究者构建了 MM1,一个参数最高可达 300 亿(其他为 30 亿、70 亿)的多模态模型系列, 它由密集模型和混合专家(MoE)变体组成,不仅在预训练指标中实现 SOTA,在一系列已有多模态基准上监督微调后也能保持有竞争力的性能。
具体来讲,预训练模型 MM1 在少样本设置下的字幕和问答任务上,要比 Emu2、Flamingo、IDEFICS 表现更好。监督微调后的 MM1 也在 12 个多模态基准上的结果也颇有竞争力。
得益于大规模多模态预训练,MM1 在上下文预测、多图像和思维链推理等方面具有不错的表现。同样,MM1 在指令调优后展现出了强大的少样本学习能力。


- 常用AI 共 188 款
- 工具箱 共 218 款
- 最新消息 共 1019 款























-
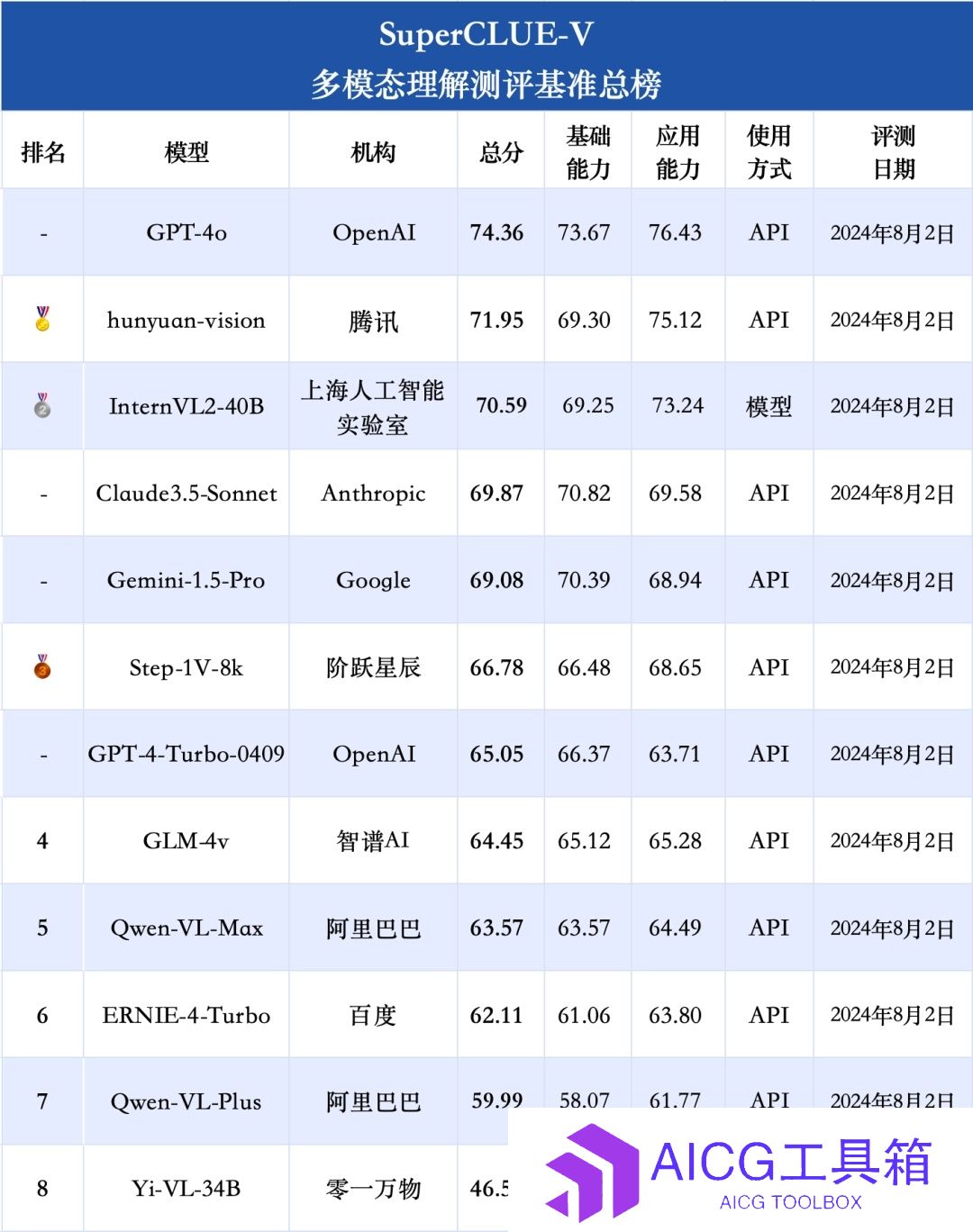
中文多模态大模型SuperCLUE-V榜单发布丨Stability AI推出Stable Fast 3D模型丨Meta AI向好莱坞明星采买声音授权
【AI奇点网2024年8月5日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
-
全网沸腾!AI大模型「开源之王」Llama 3正式发布:性能比肩GPT-4
硅谷AI大厂Meta官网上新,官宣Llama 3正式发布。提供80亿和700亿参数两个版本。有意思的是,80亿版本在某些测评项目的成绩上还超过了70亿版本。

-
华为Pura 70打造「AI抓拍」逆天黑科技,高清复原手抖模糊图像,拯救拍照手残党
近日,一段网友上传的视频,让华为Pura 70的抓拍功能意外爆火。?Pura 70中搭载了名为「XD Motion」的运动算法引擎,对照片细节进行高清复原。

-
英伟达CEO黄仁勋:人形机器人将逐渐成为主流,售价将在1万-2万美元之间
英伟达CEO黄仁勋日前参加了“CadenceLIVE硅谷2024”大会,与大会主办方进行了一场对话。黄仁勋谈到人工智能和加速计算在塑造行业大趋势中的关键作用。





-
ChatGPT如何工作_ChatGPT如何进行多轮对话
9 2025-01-26
-
可灵ai发布网页版_WAIC最新发布会_可灵官方网站
7 2025-02-18
-
Anthropic发布新一代Claude 3.5 Sonnet丨微信输入法V1.2版提供AI问答丨北京首例「AI换脸软件」侵权案宣判
9 2025-02-20
-
小米AI助理“小爱同学”接入字节跳动豆包大模型,将用于小米旗下所有「人车家」终端
4 2025-02-24
-
基准测评国内第一:百川智能发布新一代大模型Baichuan 4,发布旗下首款AI智能搜索助理「百小应」
5 2025-03-26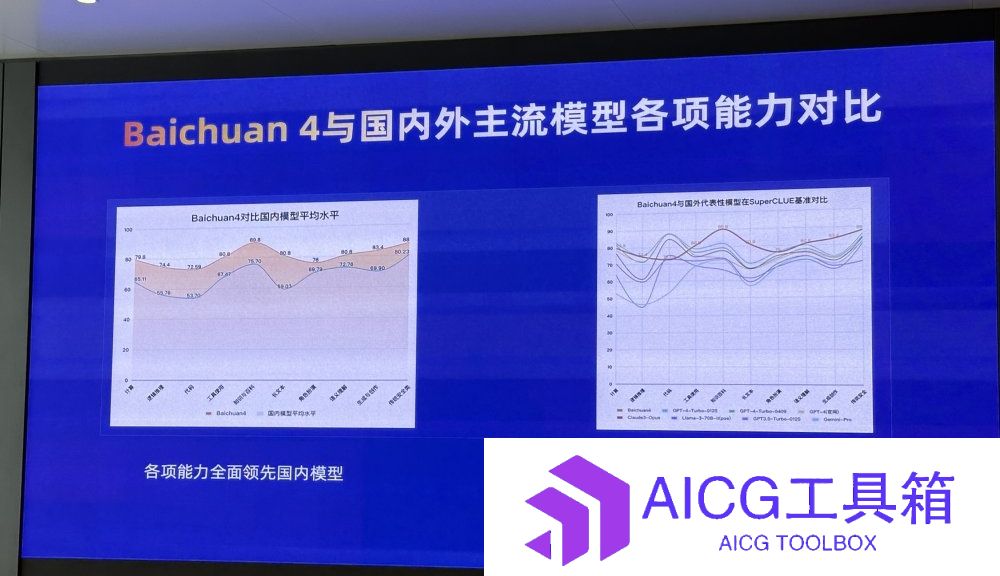
-
国产AI创业公司Kimi Chat凭200万字上下文窗口「长文本」大火,但前景可能跟淄博相似
4 2025-04-18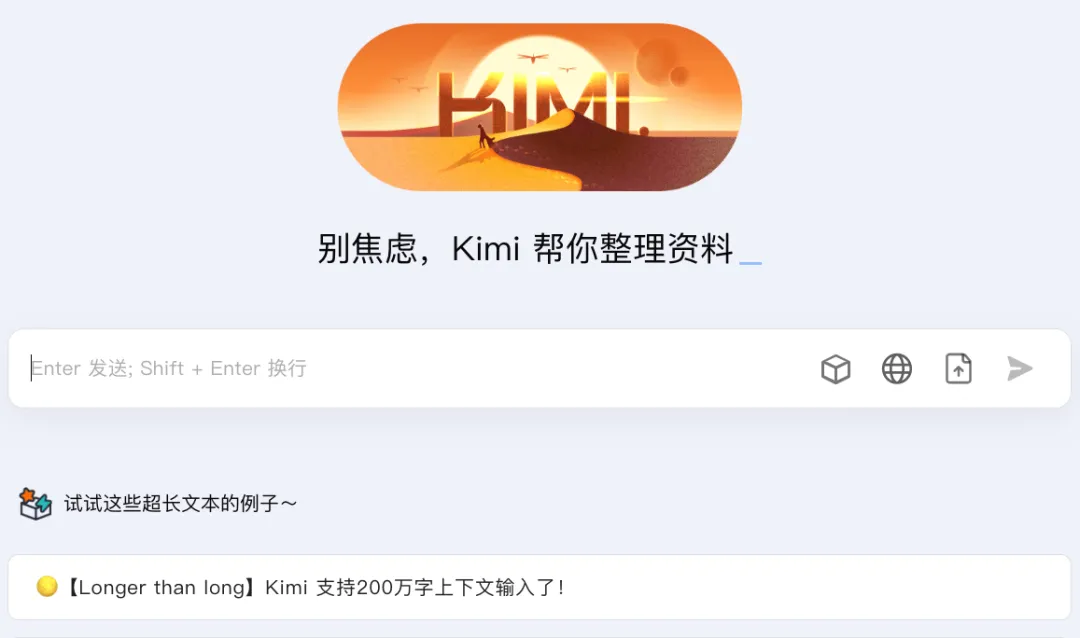
-
号外!华军AI产品榜重磅首发:8月国产AI文生视频工具大爆发
18 2024-12-25
-
讯飞星火大模型V3.5春季上新,长文本长图长语音,生产力实测:你的超级知识助手来了!
14 2024-12-26
-
国产大模型最新横评:百度文心一言5大维度21项小类测评第一,依然是国产老大
8 2024-12-27
-
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
8 2024-12-30









