谷歌发布首个多模态视频生成模型VLOGGER AI:让静态人物肖像图像开口“说话”
来源:AICG工具箱 责编:网络 时间:2025-04-19 15:17:30

近日,谷歌在其 GitHub 页面发布博文介绍一款名为 VLOGGER AI 的新模型,用户只需要输入一张肖像照片和一段音频内容,该模型可以让这些人物“动起来”,富有面部表情地朗读音频内容。

VLOGGER AI 是一种适用于虚拟肖像的多模态 Diffusion 模型,使用 MENTOR 数据库进行训练,该数据库中包含超过 80 万名人物肖像,以及累计超过 2200 小时的影片,从而让 VLOGGER 生成不同种族、不同年龄、不同穿着、不同姿势的肖像影片。

研究人员表示:“和此前的多模态模型相比,VLOGGER AI 的优势在于不需要对每个人进行训练,不依赖于人脸检测和裁剪,可以生成完整的图像(而不仅仅是人脸或嘴唇),并且考虑了广泛的场景(例如可见躯干或不同的主体身份),这些对于正确合成交流的人类至关重要”。

除了将静态人物进行动态转化之外,还可以针对不同语言系统进行口型的转换,比如将一则英语播报的主播转换为西班牙语的口型。这将有助于视频主播将内容注入更多的语言场景。

谷歌的研究团队认为,可以将 VLOGGER 应用于将 AI 聊天机器人具象可视化,比如让机器人拥有可视化的人物躯干,AI 就可以通过语音、手势和眼神交流以自然的方式与人类互动。 VLOGGER 的应用场景包括可以用于学术报告、教育场域和视频旁白等等 AI 数字人的应用领域。
围观项目主页:
https://enriccorona.github.io/vlogger/
- 常用AI 共 188 款
- 工具箱 共 218 款
- 最新消息 共 1005 款























-
B端设计教学_怎么进行UI视觉设计_B端设计教学
相信广大设计师朋友在工作中总会遇到一些B端类的视觉需求,通常是UI的装饰氛围模块以及UI视觉卡片。今天我们就来个小教程,帮助大家快速了解这类需求的设计方法和制作过程。

-
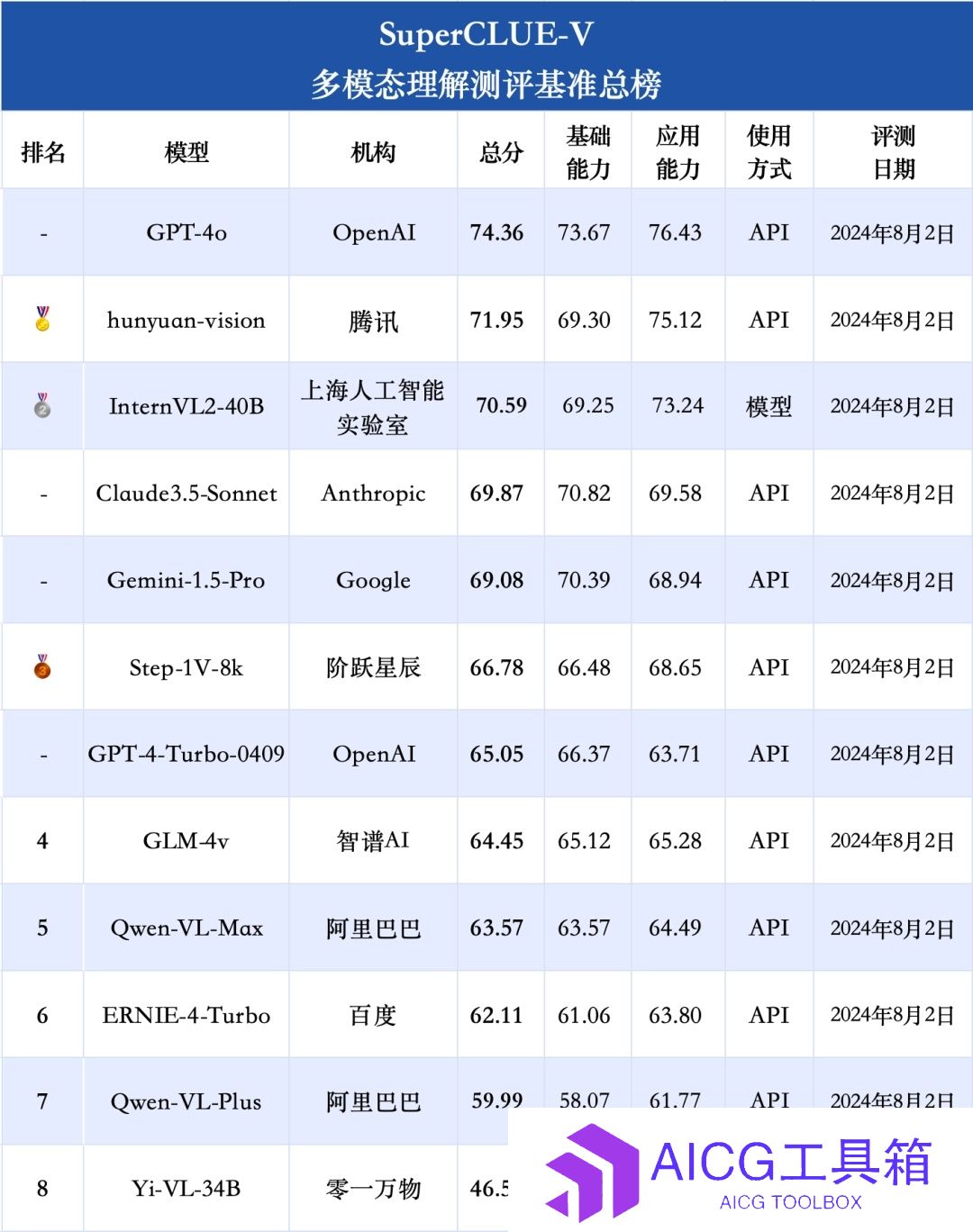
中文多模态大模型SuperCLUE-V榜单发布丨Stability AI推出Stable Fast 3D模型丨Meta AI向好莱坞明星采买声音授权
【AI奇点网2024年8月5日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
-
阿里云发布通义千问2.5大模型:号称多项能力赶超GPT-4,发布开源模型Qwen1.5-110B
阿里云 AI 智领者峰会-北京站活动中,阿里云对外发布了新版的通义千问大模型,V2 5版本大模型正式发布,该版大模型的多项能力赶超了GPT-4。

-
全网沸腾!AI大模型「开源之王」Llama 3正式发布:性能比肩GPT-4
硅谷AI大厂Meta官网上新,官宣Llama 3正式发布。提供80亿和700亿参数两个版本。有意思的是,80亿版本在某些测评项目的成绩上还超过了70亿版本。





-
B端设计教学_怎么进行UI视觉设计_B端设计教学
35 2025-01-16
-
AI绘画教程_怎么用AI创作多角度人像_多角度人像_人物多角度
14 2025-01-16
-
ChatGPT如何工作_ChatGPT如何进行多轮对话
9 2025-01-26
-
小米AI助理“小爱同学”接入字节跳动豆包大模型,将用于小米旗下所有「人车家」终端
4 2025-02-24
-
基准测评国内第一:百川智能发布新一代大模型Baichuan 4,发布旗下首款AI智能搜索助理「百小应」
5 2025-03-26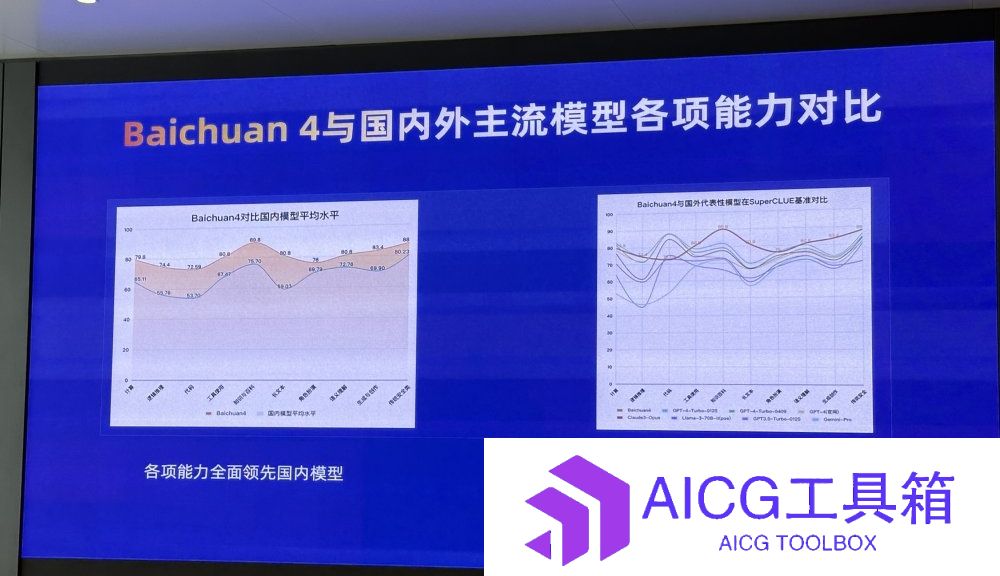
-
谷歌Gemini引发争议!网友质疑宣传片疑似剪辑效果 夸大宣传丨实测对标GPT-4测评基准有失偏颇
24 2024-12-30
-
Music To Image音生图工具是什么_AI音频生成图像工具有哪些_AI音生图工具有哪些_Music To Image怎么用
11 2025-01-06
-
controlnet怎么操作_stable diffusion模型拆解_controlnet控图的差异跟使用技巧有哪些
11 2025-01-16
-
通义听悟如何将阿里云盘文件转文字
8 2025-01-23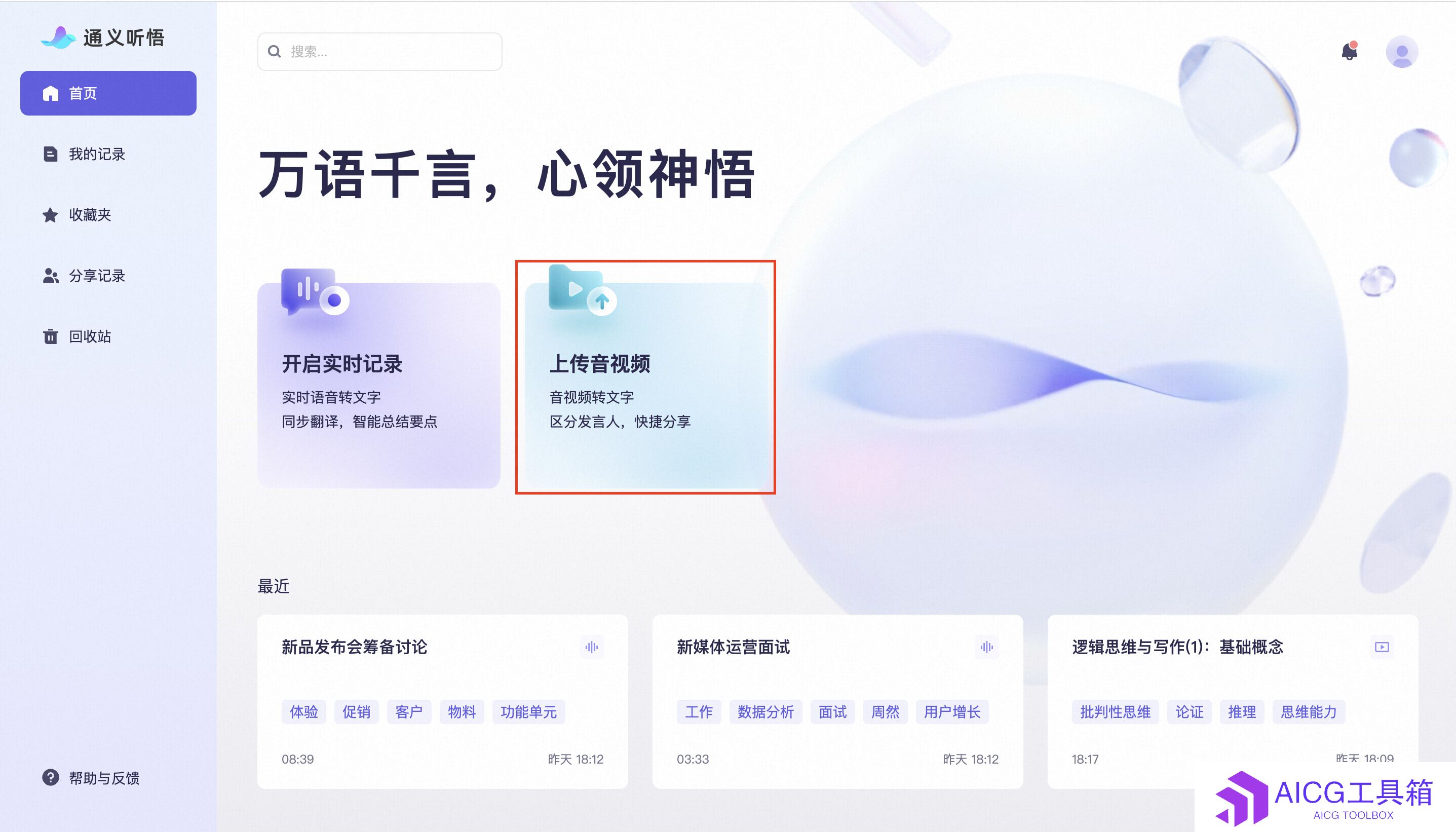
-
stable diffusion图生图技巧_stable diffusion怎么图生图
8 2025-01-26








